

Reproducible ML Workflow
This post is about a year old and things have changed since, but the gist is still true.
Every ML engineer has been there… crap where did my data go? I’ve rm -rf'd my data and model directories more often than I would like to admit. Or the phantom experiment that got 99% accuracy that nobody can reproduce? I’ve worked primarily on small, fast moving teams where any processes were met with large resistance. In my current role, my coworker, Binal, and I were able to come up with a process that was as frictionless as possible and easily reproducible for each ML project we worked on, whether image or text based.
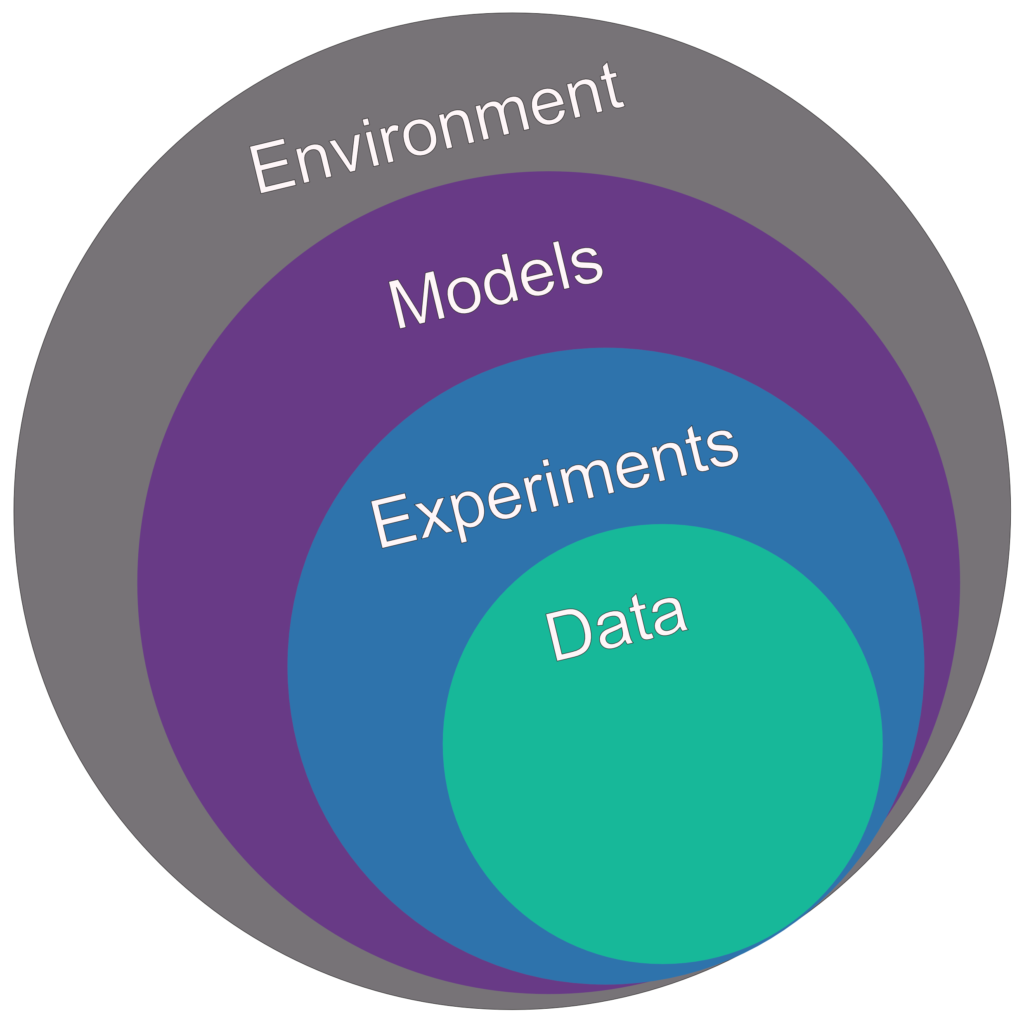
Just a few years ago, there weren’t many options for MLops, now there is an evolving set of ML tools for the Software 2.0 era. The tools range from the “you need the yet to be created instructions manual to figure out” to “the exciting, but it’s actually useless”. To frame our conversation, in this blog post I will describe the tools I use primarily for data analysis, model ideation and training, and finally exporting a model for deployment. We will leave production model serving and performance and model drift tracking for another conversation. For our team, we wanted the flexibility to work in Jupyter Notebooks for rapid data analysis or command-line interfaces for training and model conversion. Further, we wanted to track everything about a model the:
- Data
- Experiments
- Models
- Environment
In the rest of this blog, I will describe each element and what tools we used. In future posts, I will create tutorials and ideally a cookie cutter project to follow for your own projects.
Data
The data is at the core of any ML project, it feeds the model and, in my experience, it is often more important than model selection and where most errors occur. There are several states data can be. I’ll use face recognition as an example. You have the raw images, from which you conduct face detection, crop the faces, and possibly perform face alignment. Without data versioning, you could lose track of which set of images you processed for face detection, or worse delete them completely having to start from scratch. Further, as a project progresses, faces that are not faces, too blurry, etc. may need to be further processed or cleared from the training set. Again without versioning, the old version of the set is lost once a file is moved and any models trained on that version loses reproducibility. Enter Data Version Control (DVC). With DVC each step of a data pipeline, code, images, and their outputs are versioned.
download_images.py → images_folder → detect_faces.py → face_detections_folder → align_faces.py → aligned_faces_folder
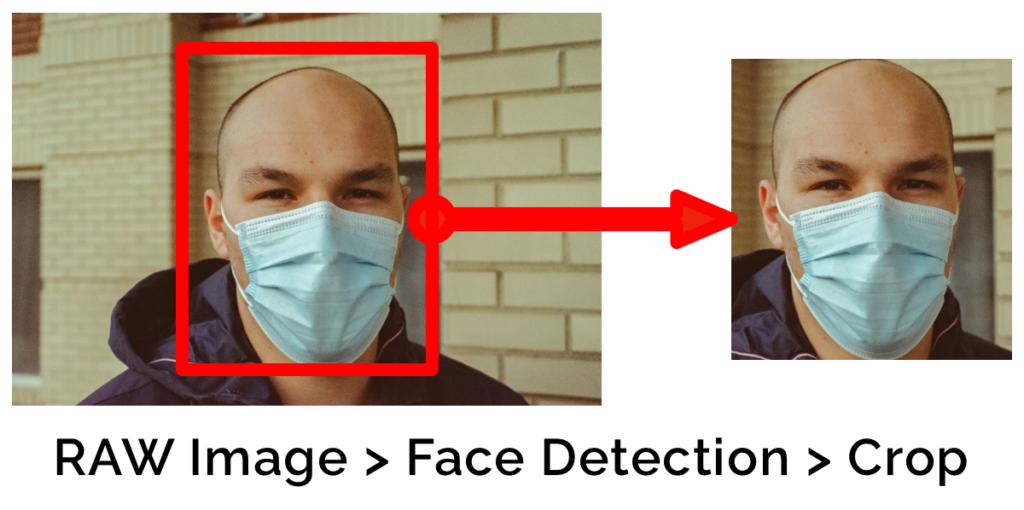
In the above example, DVC versions the hash of the files used, but each data input/output for full reproducibility. Completed stages are skipped. Data is stored in the cloud. And it is fast due to their data caching and linking mechanism, which you can mount as a persistent drive to new training instances.
Experiments
During model development, there are many iterations. Git versions the code and parameters, however anybody using Tensorboard knows how nice it is to visualize everything as the model trains, compare losses, accuracies and other metrics across different runs. Anybody using Tensorboard on a team, on distributed servers, or for longer than a few experiments also knows its weaknesses. If you want access to all experiments across servers, there are several options. The de facto option is MLFlow, which can be run locally or hosted on a server in the cloud. I personally think the interface is lacking and requires way too many clicks, petty I know. My personal favorite is Weights&Biases. I’ve tested many of its competitors and I admire their quick and prioritized response to user requests and their interface is not ugly; I appreciate a good UI. Finally, if you’re strapped for cash then MLFlow is probably good enough and you can move on.
In my projects, I push experimental results to wanbd, commit the project id to my git history, and dump all summary results to dvc versioned using the metrics API, which is great for viewing and comparing results from the command line.
Models
The final output of each experiment is the model. I use a snapshot selection criteria for each project and commit the “best” model via dvc. Because of dvc’s pipelining I can easily add extra conversion steps for each platform I’ll run on, e.g. iOS, Android, and ONNX.
Environment
A teammate sends you a model and some evaluation code. You spend 3 days setting up your computer after finally figuring out it only runs with a 2 year old version of tensorflow and cuda 1.0, don’t get me started with cudnn. #storyofmylife This game of hide and seek is unrewarding and frustrating to say the least. To avoid this we agreed on a combination of Docker and conda environments. With Docker we have operating system level versioning and with conda we version everything else, cuda, software packages (mostly here, otherwise apt-get it in Docker), and python packages.

Wrap Up
With all of these components we have an organized, reproducible solution that is versioned via git: the environment versions the os, software, and all packages used to run experiments and models. The experiments are versioned via git+dvc and visualized with tool agreed upon by the team, e.g. wandb. Finally, the entire pipeline that produces the data and models is versioned with dvc. The tool that really pulls everything together is dvc. I highly recommend you try out their tutorial. If you all want, I’ll right one showing how I use it in my own projects.
Extra Notes
I’ve been keeping an eye on DAGsHub. It is a compelling solution because it combines git, dvc and mlflow into a single service eliminating the need to host your own storage, credentials, etc. Has anybody used it?
A new version of DVC came out while I was working on this pos. New features include better experiment management and tracking. I need to use this improved feature, but it still seems limited for those used to using Tensorboard, mlflow, etc. It seems early to make any verdict as it’s evolving quickly, I’ll be watching this feature closely.
Coding standards are important too which you can remind everyone about through git pre commit hooks. It will require a few seconds extra when pulling/pushing a new repo, but worth it in the long run.